主要介绍常用的两种引擎MyIASM、InnoDB。
基本的差别为:MyISAM类型不支持事务处理等高级处理,而InnoDB提供事务支持以及等高级数据库功能。 MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快,但是不提供事务支持。
还有一些细节方面的区别:
- 对于AUTO_INCREMENT类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引。
- DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除。
- InnoDB 中不保存表的具体行数,也就是说,执行select count() from table时,InnoDB要扫描一遍整个表来计算有多少行, 但是MyISAM会缓存表的meta-data(行数等信息)。 但是当count()语句包含 where条件时,两种表的操作是一样的。
select count(*) 和order by 是最频繁的,大概能占了整个sql总语句的60%以上的操作, 而这种操作Innodb其实也是会锁表的,很多人以为Innodb是行级锁,那个只是where对它主键是有效,非主键的都会锁全表的。 所以InnoDB表的行锁也不是绝对的,假如在执行一个SQL语句时MySQL不能确定要扫描的范围, InnoDB表同样会锁全表,例如update table set num=1 where name like “%aaa%”。
再谈谈索引结构,innodb是聚集索引结构,MyIASM是非聚集索引结构,简单的说这两者的区别就在意数据是否和索引在一个节点上。
innodb和MyIASM的索引用的数据结构都是B+Tree
B+Tree的特点:
- 非叶子结点的子树指针与关键字个数相同
- 为所有叶子结点增加一个链指针
- 所有关键字都在叶子结点出现
- 内节点不存储data,只存储key
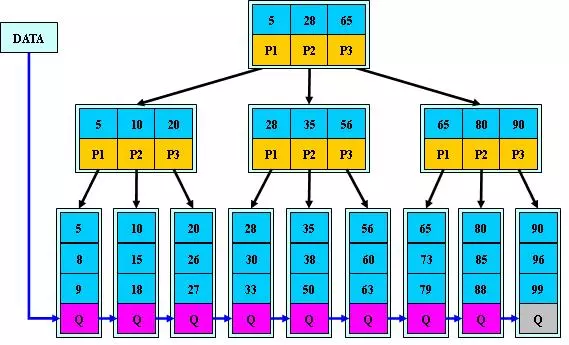
简单谈谈聚集索引,先熟悉下B+Tree这种数据结构。 在大部分的数据库索引结构中大多数都采用的是B-Tree的变种即B+Tree, 甚至在B-Tree上再改造,节点之间添加顺序访问指针,做这个优化的目的是为了提高区间访问的性能。 同时因为读取磁盘的时候会有预读,B+Tree的数据结构性能更好。
MyIASM索引文件和数据文件是分离的,其索引文件仅保存数据的地址。
MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,
如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。

innodb是聚集索引结构,其数据和索引是在一起的,数据文件本身就是索引文件。
 InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域.
聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域.
聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。